Announcing Calf, an open source implementation of Narwhal

Today we're excited to introduce Calf, the first fully open-source implementation of the Narwhal DAG protocol. While DAGs represent a powerful advancement in blockchain technology, educational resources and practical implementations remain scarce. We've created Calf not just as a working implementation, but as a foundation for learning and collaboration. By making this technology more accessible, we aim to inspire developers and researchers to explore, contribute, and advance the field of DAG protocols.
Why
At Pragma, we're building oracles to enable more efficient markets. We believe blockchains will power the next generation of financial infrastructure, fundamentally reshaping how markets operate. To advance this vision, we're developing the fastest oracles in the space, enabling multiple parties to instantly agree on market states. To make this possible, we've built a new infrastructure layer that combines maximum censorship resistance with the speed necessary to handle the world's real-time data.
This infrastructure is being developed as a DAG-based protocol, as it is the only way to support the load we're handling, with low-latency requirements. We quickly realized while working on DAGs, that there were few resources available, especially from an engineering perspective. We think this has led to the industry overlooking DAGs because they were too complex both to understand and implement, as well as to maintain in a production system.
It's time for a change.
What
Calf is an open-source implementation built from the ground up of Narwhal, a mempool protocol optimized for DAGs. It separates the dissemination of data from the consensus, which makes it very efficient. To our knowledge, it's the DAG protocol that has been most widely used in production to date. Yet there is still not much information available about it. Calf is the first step towards a global industry mindset change—let's make DAGs great again and compete with leader-based BFT protocols. To achieve that, we need to make them easy to understand and experiment with.
The complete repository can be found here. Everyone is welcome to contribute to this first building block of a larger knowledge base for DAG protocols.
Calf includes the following:
- An opinionated implementation of Narwhal
- Python scripts to launch it and experiment with the hyperparameters
- A new standard for DAG animations
Learnings
Throughout this work, we've learnt a few things worth sharing to understand better the trade-offs with such a protocol in practice.
Due to the scarcity of educational resources about DAG protocols, we'll begin by defining the fundamental concepts and terminology:
DAG :
DAGs are Directed Acyclic Graphs. Like regular blockchains, there is a notion of epochs where 'blocks' are finalized. However, instead of having one block, there is a round of many blocks, each containing transactions issued by all nodes. So rather than a linear blockchain, you have a graph like this:
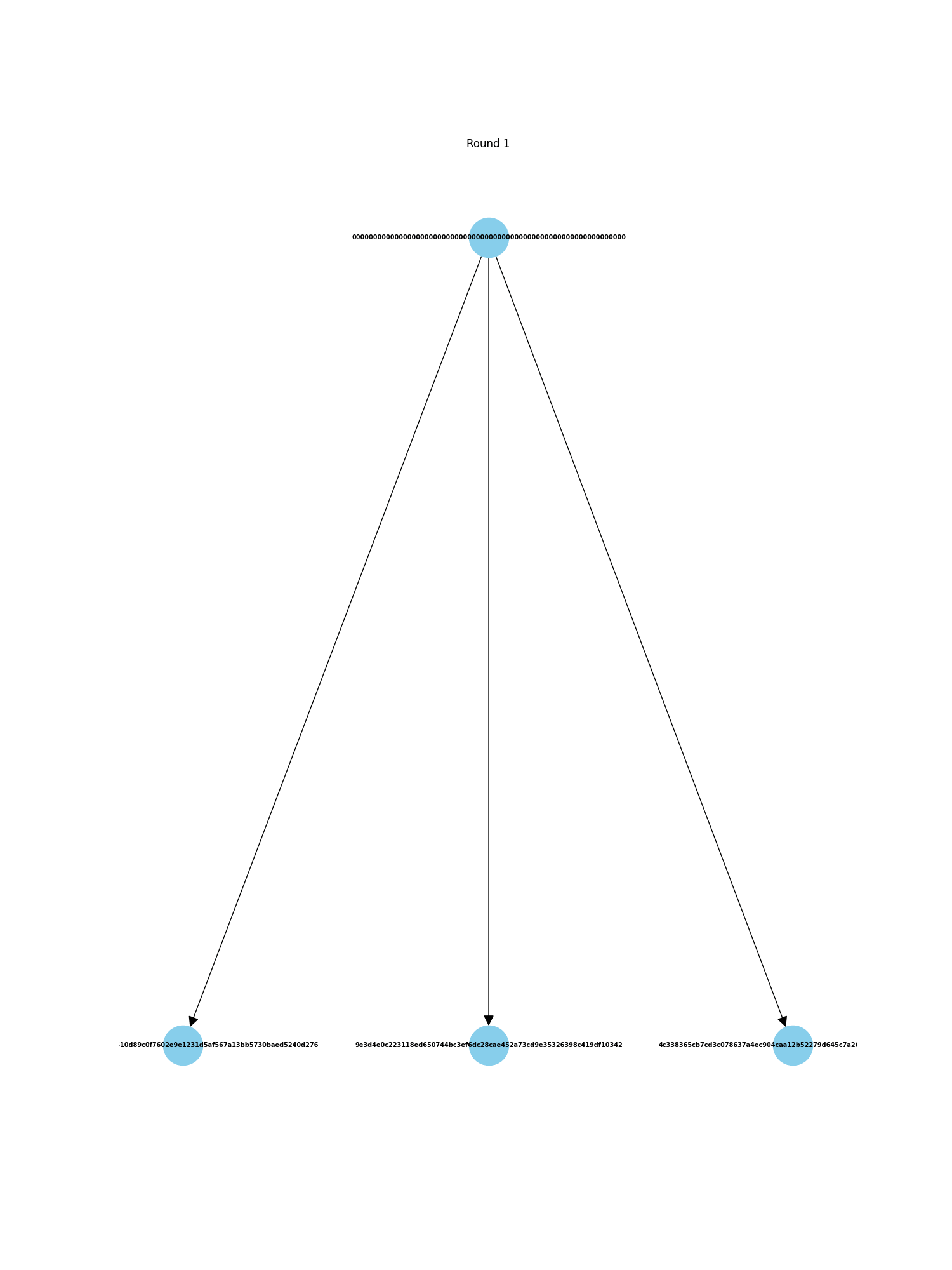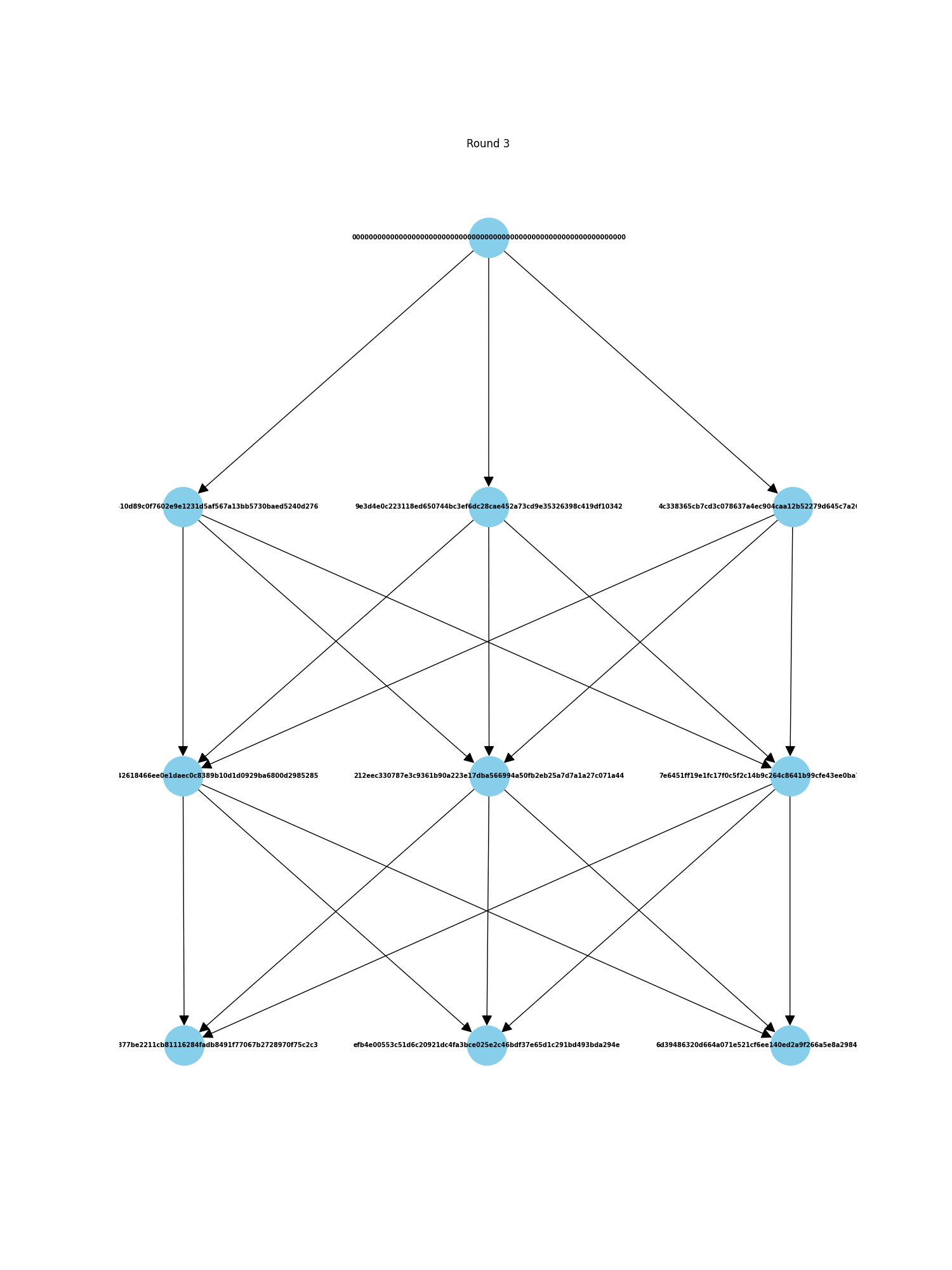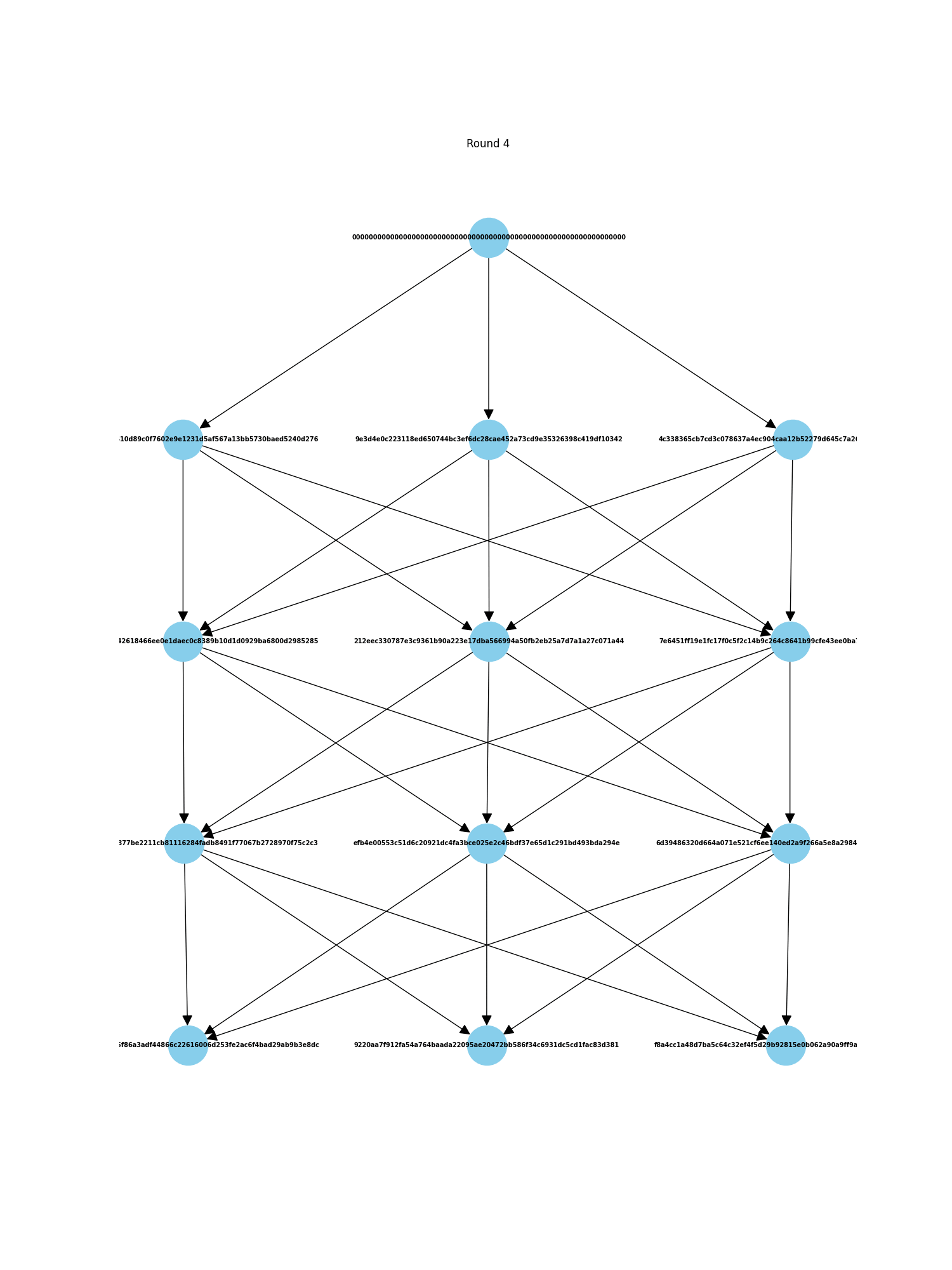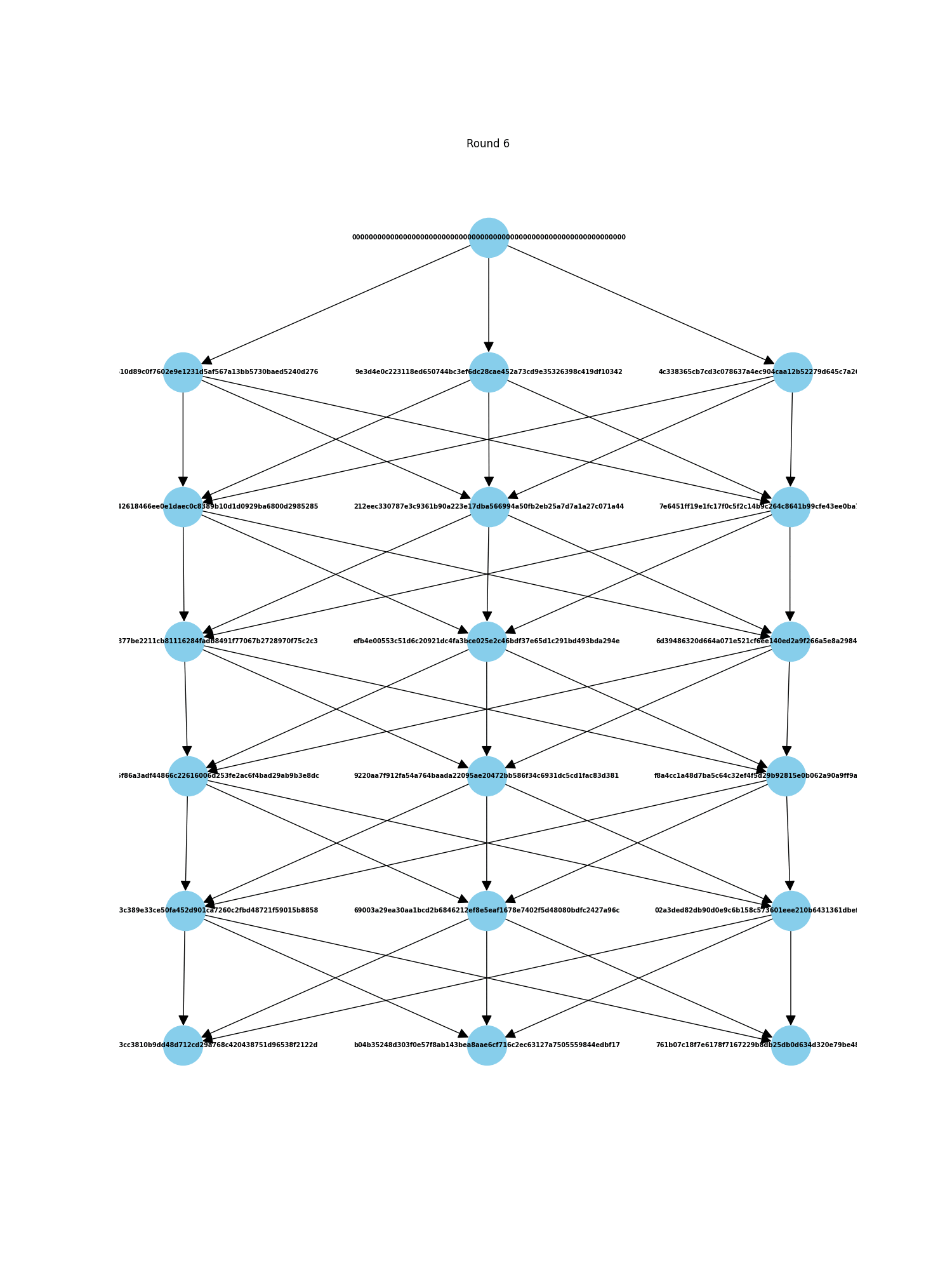
Because each node produces its own block, this kind of system has high scalability in terms of transaction handling—you only need to add another node to handle and finalize many more transactions simultaneously. More nodes mean better decentralization for the whole system, although decentralization may be limited in the early stages, which poses a potential issue. The system also has security concerns, such as Sybil attacks, which is why we use the concept of quorum for block validation.
Quorum:
To validate a block, we need a quorum of nodes that ensure it is correct. A quorum is reached when 2f+1 nodes vote for a block, where f is the number of byzantine (malicious) nodes in the network. This system helps reach finality faster while preventing malicious nodes from altering the network. However, this can significantly slow the throughput if poorly designed.
Now that being said, let's see what we learned from reimplementing Narwhal.
Narwhal:
Narwhal is a DAG-based mempool that works with two kinds of components: Worker and Primary. Each node has one Primary and many Workers (the amount of workers is defined by a global parameter). The Worker's role is to handle incoming transactions and process them. It then constructs a batch of transactions and sends it to other workers with the same ID - e.g., worker 1 of node A broadcasts its batch to all worker 1s of other nodes and then waits for a quorum of acknowledgments from them. Once a quorum is reached, it stores the batch in its database and sends a digest of this batch to the Primary.
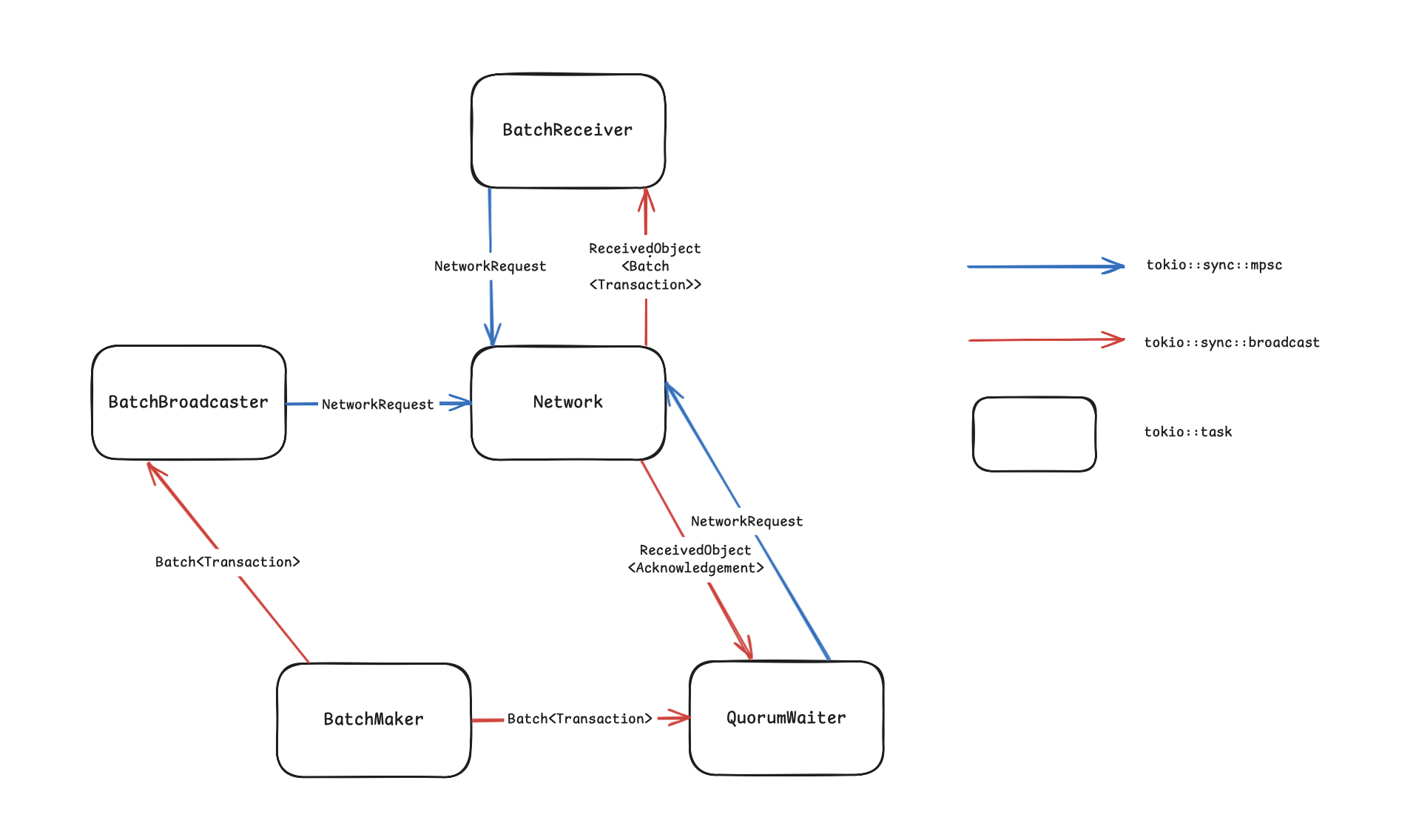
The Primary's role is to build the DAG. It receives digests from all its workers, then constructs a header with them and a list of IDs with parent certificates (at least 2f+1) from the previous round and proposes it to other nodes' Primaries. Other nodes will receive the certificate, and if it's the first received from this authority, they will send back a vote to the sender. Once we reach a quorum of votes, the Primary generates a certificate and puts it in the DAG for the current round.
As you can see, it is a very effective system, but it's quite complex, and it should not be surprising that we struggled at times implementing it.
The first difficulty we encountered was that, within a node, all the components are made to run on different machines, so the communication between elements became more difficult as we must use P2P components instead of Tokio channels. As Calf is an educational project, we used mDNS discovery to enable visibility between components. Following the paper's design, it should be possible to have one worker on a computer somewhere and another in a data center on the other side of the world. Now that we can discover every possible component that uses our communication protocol, we need to know if each component belongs to our node or another node, so we added an identification method using a keypair that will be used by the node.
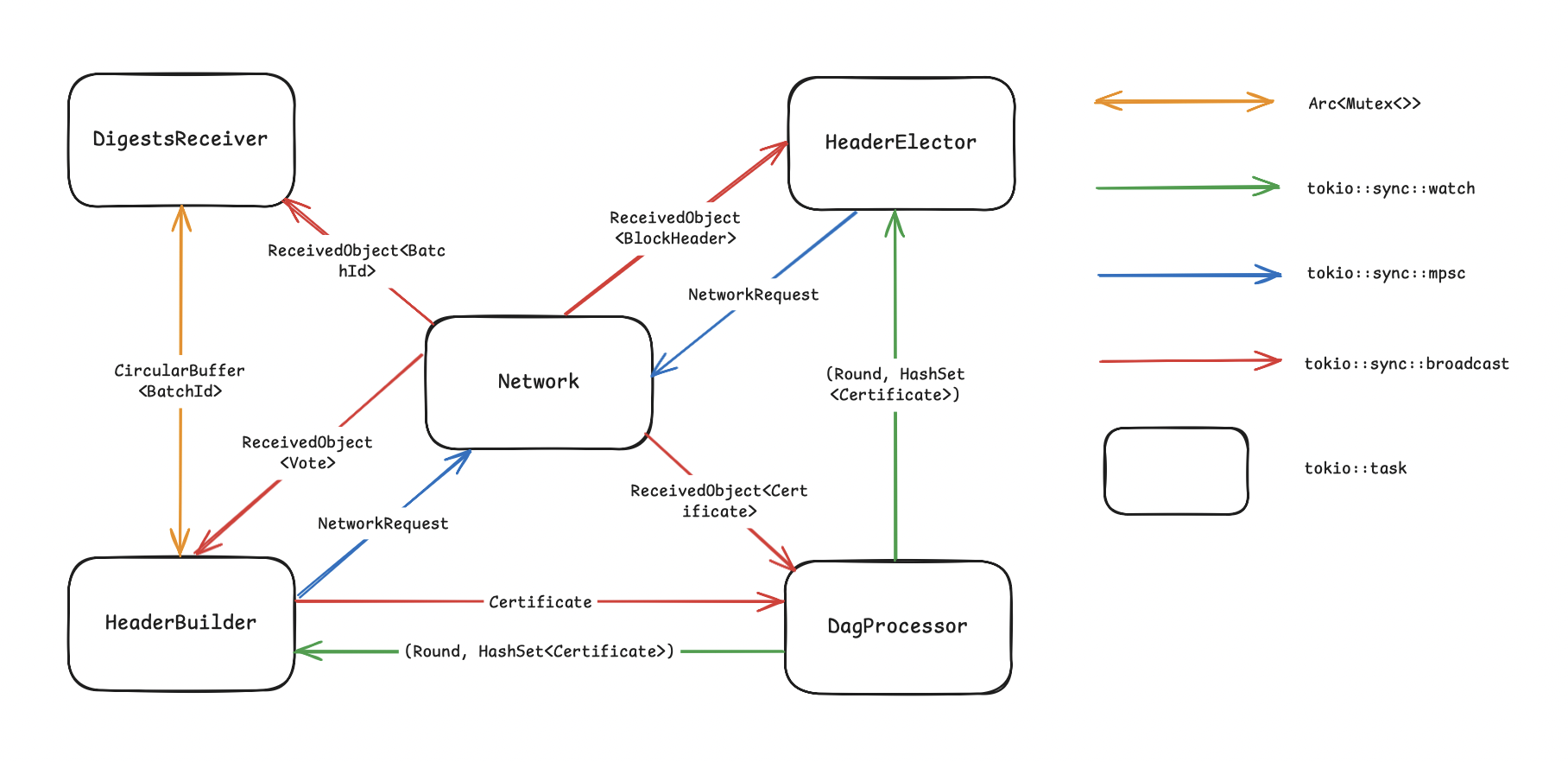
Now that we have a fully-connected working node, the real challenges begin. While Narwhal demonstrates excellent CPU performance and scalability, the network emerges as the primary bottleneck. Since all components communicate through the network, it must handle a diverse array of message types including Batches, Certificates, and Headers, along with numerous simultaneous connections. After implementing these message types, careful management of message frequency becomes crucial to prevent network flooding. While this isn't a significant issue during normal operations, it becomes critical during the most challenging aspect of the system: node resynchronization.
During our research on Narwhal, we came across a presentation by Alberto Sonino at UCL where he discussed their main engineering challenge: overlooking synchronization in the initial design process. This oversight resulted in significant time spent retrofitting synchronization into the system.
The first complex challenge is handling new node integration. When adding a new node to the system, it needs the complete historical data to produce new certificates. While it might seem obvious that the node should request historical data, this raises an important question: who should provide this data? Using a master node would introduce centralization, which is undesirable.
The solution we implemented allows every node to share its historical data. When a new node joins the network, it sends a synchronization request message to begin the process. However, this straightforward solution from the new node's perspective raises another challenge: how should existing nodes handle synchronization requests? They cannot simply halt operations to send historical data, as the blockchain must continue operating when new nodes join. Instead, they must transmit historical data in parallel with their normal operations. This parallel transmission, combined with the large volume of historical data, leads back to the network bottleneck issues discussed earlier.
This, however, only addresses the case of a new node joining the network, requiring a 'Full Sync.' We must also consider scenarios where existing nodes need to reconnect after shutdowns caused by hardware failures, network issues, or storage limitations. In these cases, we perform what we call a 'Partial Sync,' where the node must first determine what data it missed during its downtime, in addition to handling all the synchronization challenges mentioned above.
With all that being said, we decided to design our resynchro component like this :
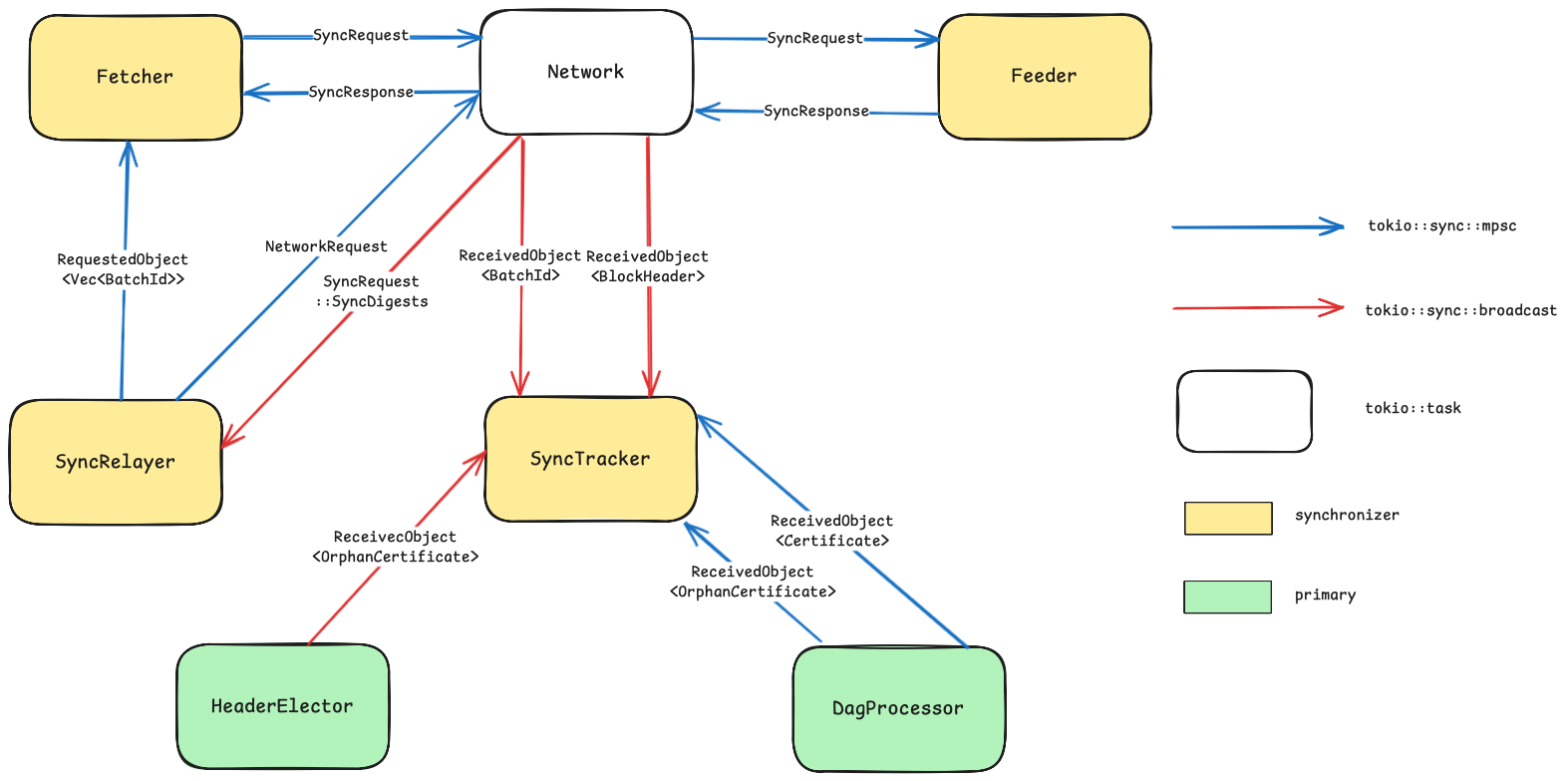
The synchronizer consists of three main components: the Primary's SyncTracker, the Fetcher, and the Feeder.
The SyncTracker is responsible for identifying missing data that needs synchronization, tracking data reception, and monitoring the node's synchronization state.
When the sync_tracker identifies missing data (such as parent certificates referenced by a received valid certificate), it sends the IDs of the required data to the fetcher. The fetcher then retrieves this data from peers and dispatches it to the tasks that need it.
A special case arises when the data to be synchronized is a digest corresponding to a transaction batch. This data requires retrieval by a worker through the following process: a SyncDigests request is sent to the worker, which processes this request via the SyncRelayer. The SyncRelayer uses the Fetcher to retrieve the relevant batches, which are then transmitted back to the requesting Primary.
Finally, the Feeder handles incoming data requests by searching the node's database for data that matches received SyncRequests.
Conclusion
If you're interested in experimenting with Calf, exploring the codebase, or contributing to the project, please check out our GitHub. Whether you're a seasoned distributed systems engineer or just getting started with blockchains, your perspective could help shape the future of DAG protocols.
Feel free to open issues, submit pull requests, or reach out with questions. Let's work together to make DAG protocols more accessible and practical for everyone.
Thanks a lot to Alberto Sonnino and the Sui engineering team for the guidance and help building this.